Well, it’s about time that I start to nag about spam again. This time someone really would like people to go trade on the financial market. Preferably in mining company called “Inspiration Mining Corp” or simply IRMGF. And yes, this is very important since the spammer wants to make a huge profit from selling his shares to you so the price needs to go up fast.
IRMGF is a so-called penny stock. This means the price of it is so low, it only costs a penny to own a piece of the company. Basically, it’s almost worthless but for some it’s still interesting to trade in. Why? Because if the price goes up just a single penny, those investors will have doubled their investment! So if you buy 100,000 in stock for a penny each and manage to increase the price by just 2 cents, then your $10,000 investment will now be worth $30,000. Which is not bad for a reasonable small investment.
Problem is, with stock you never know if the price will go up or down. So it is interesting to try to manipulate the value of penny stock in all kinds of ways. The simplest way is by making people believe how ‘cheap’ the stock actually is, hoping people will start buying. And sure, some of those buyers will pay about the same as the spammers do, about a penny per stock. But this will also start to increase the value of the same stock, since people want to buy it.
But when the stock price has doubled or tripled, the spammer will immediately sell his stock to those who still continue to buy it. The spammer will earn a nice profit and has almost no risk of getting caught. (Unless it can be proven that he was responsible for the spam.) Since lots of people will buy and sell penny stock it’s just not easy to find the person who has spammed among all those suspects.
So, lets take a quick look at the IRMGF:US stock here at Bloomberg. The price has moved between 4 cents and 16 cents during the whole year. If you bought stock in December 2013 and sold it again in May/June 2014 then you would probably quadruple your investment. Not bad for just a few months waiting. But now the price has dropped to below 7 cents per stock so it is interesting to start buying again, hoping the price will go up again.
Then again, this is how the stock market works. You buy stock as an investment to keep your money safe. If things go well, you should make a small profit on your investment. If not, you should sell before the stock becomes worthless. Most people with money don’t really buy stock to make profits but to make sure their money is reasonable safe. But they will have to check the market continuously to make sure their stocks are stable enough. This is a bit time-consuming and many investors will use computers to watch the stock market for them. And probably hire a financial advisor who does nothing else but trade in stock to keep the invested value stable.
Penny stock is reasonable unreliable because the low price suggests that the company behind the stock isn’t doing so well. If they have to file for a chapter 11 because the company is dead broke, your stock will become worthless. You’d rather invest in something more stable and reliable and start selling it when you expect its value to drop.
Now, why do I start about this spam? Well, simple. For the last 5 days I’ve received hundreds of spam messages on various of my email aliases. This is practical because it tells me which companies have shared my mail address with those spammers. Adobe and LinkedIn are, of course, the usual suspects because their databases have been hacked. As a result, I still receive lots of spam on those aliases. Another company that apparently got hacked is SmithMicro where I purchased my Poser software for the CGI models.
I also noticed strange addresses like waterside__9.jpga@example.com and tayen-usenet-a@example.com which I never even created. I don’t know why those spammers are using those aliases but maybe the person who owned the specific domain before I did used those accounts.
What do the messages look like? Well, like this:
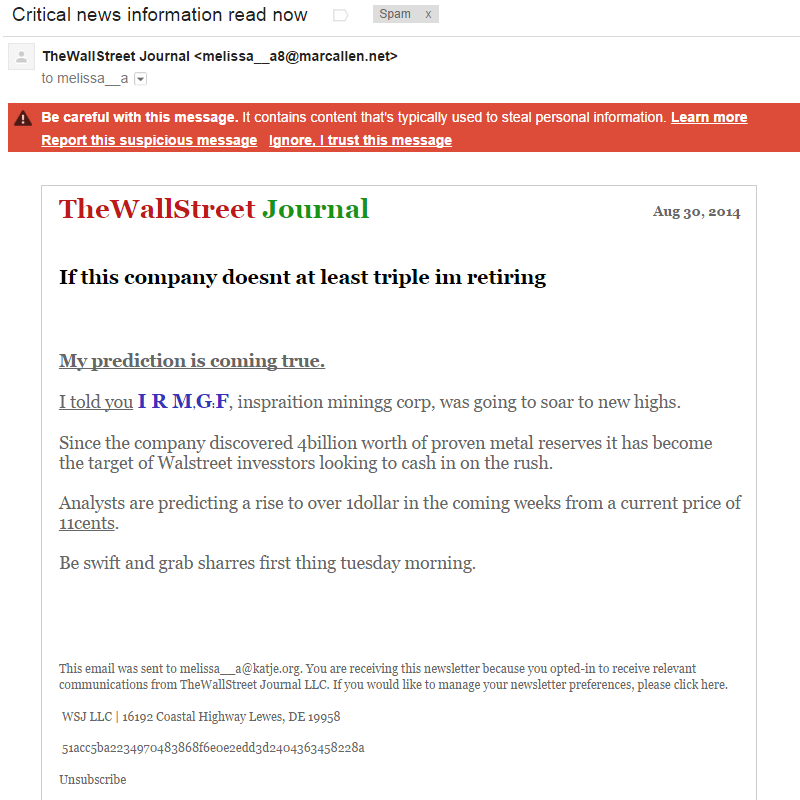

And there have been more variations of this spam.
A few things are easily noticeable. First of all the spelling in both messages is just plain bad. They included other characters in the stock name, spaces are missing in some places, “mining” is spelled wrong and a few more things. This is done on purpose to get around spam filters, although it just doesn’t seem to work with the Google spam filters.
The sender happens to be fake, though. All spammers will use fake email accounts, often collected from their own spam lists to make it seem legitimate. So responding to the sender or anyone else in the email is useless. You’d just be harassing some other innocent person. Yet many people do think it helps so they respond to complain about the spam. Or report the account to their ISP, accusing them of spam. Most providers are smart enough to recognise this, though. They won’t take actions against the fake sender because they know he’s just a victim too.
The email also has several links to make it look more legitimate. But in this case, even those links are fake. They are a combination of the email address (the part before the @ sign) and some gibberish with .com or .org after it to generate a domain. It also includes a path on the fake domain that looks legit but since the domain is fake, the whole link is fake. This spammer just doesn’t want anything that would link back to him.
So, would the IP address in the email header be any helpful? Unfortunately, not much. The computer behind that IP address is most likely part of a bigger botnet. A machine infected by malware that the spammer can use to send his spam. You could report the IP address to the related provider and hope the provider will take the specific user off the Internet until he has cleaned his computer but in general, that’s not going to happen.
Thus, these spam messages are hard to stop. The spammer is difficult to trace since a lot of people will be trading in this penny stock. Some investors might even consider investing in it since they expect the price to go up even further because of this spam. As I said, the price has been over 16 cents at one point and now the price is 11 cents. If it continues to go up, they could still make profit from it.
Nothing in the email will lead back to the original spammer, although it will expose the computers that are part of the botnet. Those computers should be taken offline but doing so is not that easy. To make it more complex, those IP numbers could just be connected to a router and a lot of computers might be behind this router. There could even be an open WiFi connection in the router that happens to be misused by someone else in the area. (Who could be innocent too, but his computer could be infected.)
Penny Stock Spam is a very difficult one to fight against because the spammer can hide himself very well. He doesn’t have to add a link to his webshop or to some infected website that could be closed within a day after it has been reported. There’s almost no trace to the spammer either. The only thing that helps against this kind of spam is to not buy the stock, not even if you’re an experienced investor and still expect some profit. You will most likely lose money on those transactions because you’re just paying the spammer himself.
But if you’re lucky, a bigger moron will still buy the stock and give you some profit. And that’s the worst part of this spam. It’s not just the spammer who will profit but some investors might also have a smaller profit from it. As I said, if it goes up just a cent, they would have made a huge profit already.