I’ve been programming for a very long time. I wasn’t even 10 years old when I got access to computers and that was back around 1975! My first programming experience were on a programmable calculator and later with BASIC on a ZX-81. Around 1985 I started learning other programming languages and around 1988 I even used Turbo Pascal 5.5 which has support for object-oriented programming. Well, a bit limited.
When I started using Turbo Pascal and later Delphi, I also learned the value of methods that would return objects. But it would still take a while before I realized the full power of this. Still, in Turbo Pascal 6 there was a feature called Turbo Vision that could be used to create complete menu structures and dialog screens on a text console! It made extensive use of methods returning objects to make method chaining possible.
Method chaining is a simple principle. You have a class and the class has methods. And each method can return an object of a specific class. So that gives access to a second method. And a third, a fourth, a fifth until you get to a method that returns void.
That’s a dead stop there!
I recently worked on a project where I used a long method chain to keep a clear workflow visible in my code. And my code was selecting data, ordering it, manipulating it and then saved it to a comma-separated file or CSV file. Something like this:
But SaveToCSV was a method that returned void, so the chain breaks there! But I wanted to continue the workflow as I needed to do more with this data. I also wanted to display it on screen, save it to a database or even filter it a bit more. So, to resolve this I needed a better method that would allow me to continue the chain.
Of course, I could also have written my code like this:
var myList = MyData.ToList(); var mySortedList - myList.OrderBy(SortOrder); var myTop50 = mySortedList.Take(50); var myNewList = myTop50.Select(NewDataFormat); myNewList.SaveToCSV(Filename);
This code would allow me to also continue the workflow and would also allow me to use myNewList for further processing. But it also introduces a bunch of variables and it allows non-related code to be included within these lines, obscuring the workflow! That would not work! The chain of work would be broken by irrelevant tasks.
So, now I have two options. Either I modify the SaveToCSV method so it will return a value (preferably the object itself) or I make an extension method inside a static class that would allow me to put a void method within my chain. And I came up with this beautiful, yet simple method:
public static T Do<T>(this T data, Action<T> action){ action(data); return data; }
And this simple, yet beautiful construction is a generic method that can be used for any class, any object! And it can change my code into this:
Now my data flow is still intact and the flow of the code is still very readable. It is easy to see that this is just one block of code. Most people tend to forget that programming isn’t about writing code. It’s about how to process data.
Using a method chain is a perfect way to visualize data flow inside your code. But to allow proper method chaining, each method will have to return some kind of object for further processing. Otherwise, you will need a Do<> extension method in your project to make a void method part of the chain.
But to keep it simple, when using a void method, you’ll basically put a stop to the data flow within your application. You would then have to start a new data flow for further processing. This is okay, but generally not the best design in programming. While not everyone might be a fan of method chaining, it still is a very powerful way to write code as it forces you to keep irrelevant code outside of the flow.
Stallman is also known to avoid anything that could be used to follow his actions. He considers mobile phones to be “tracking devices” so he refuses to own one. He also avoids browsing the Internet directly and uses an email-based proxy instead to read content from various websites. And he uses the Tor network in recent years, just to stay anonymous. And more importantly, he’s very active in making software freely available for everyone at no costs, fighting against copyrights, patents and more.
So, Stallman is a pretty important force in the ICT World. He has a lot of followers, a lot of admirers. Especially many students are happy with him as he made it possible for them to get software for free. How? Because Stallman promotes open source with the preference for the GPL license. And the GPL license is a license system that could forcibly be used to make other projects open source also, if those other projects use any GPL’d code…
And while open source has been popular before Stallman started the GNU project, it did become very popular after GNU. Especially after Linux became a thing and the world suddenly started to get new, free operating systems that could be ported to many different systems. And while there are many other open source licenses, the GNU license became popular as it is an open source license that adds restrictions on how you can use any of it. Some consider the GPL to be contagious as the use of GPL code in your project will force your project to be part GPL, thus forcing you to publish some of your own code as open source. Which was disliked by many companies. But the end users love it…
But recently, Stallman made a huge mistake. He wrote an email defending Jeffrey Epstein… Epstein was arrested on federal charges of sex trafficking of minors and has been convicted in the past for child molestation and prostitution. Serious charges but Epstein’s apparent suicide a month after his arrest put an end to the case, although a lot of people still doubt Epstein killed himself. It’s all too suspicious. And by defending Epstein, Stallman will now become part of any future conspiracy theories.
Which is bad, as Stallman is single, never married, never had children and we don’t even know if he has any sexual preference. He could be asexual, bisexual, hetero, gay, pansexual. Not that it matters, but people will start wondering about this now. After all, why would Stallman get involved in this whole affair.
So, what did Stallman say in his email? Well, from a source, I got this anonymized version:
The announcement of the Friday event does an injustice to Marvin Minsky: “deceased AI ‘pioneer’ Marvin Minsky (who is accused of assaulting one of Epstein’s victims)”
The injustice is in the word “assaulting”. The term “sexual assault” is so vague and slippery that it facilitates accusation inflation: taking claims that someone did X and leading people to think of it as Y, which is much worse than X.
The accusation quoted is a clear example of inflation. The reference reports the claim that Minsky had sex with one of Epstein’s harem. (See https://www.theverge.com/2019/8/9/20798900/marvin-minsky-jeffrey-epstein-sex-trafficking-island-court-records-unsealed.)
Let’s presume that was true (I see no reason to disbelieve it). The word “assaulting” presumes that he applied force or violence, in some unspecified way, but the article itself says no such thing. Only that they had sex.
We can imagine many scenarios, but the most plausible scenario is that she presented herself to him as entirely willing. Assuming she was being coerced by Epstein, he would have had every reason to tell her to conceal that from most of his associates.
I’ve concluded from various examples of accusation inflation that it is absolutely wrong to use the term “sexual assault” in an accusation. Whatever conduct you want to criticize, you should describe it with a specific term that avoids moral vagueness about the nature of the criticism.
I’ve underlined “Epstein’s harem” as Stallman refers to Epstein’s underage victims here in a very unflattering way. It’s a bad remark, and it’s costing him dearly. He clearly misunderstands the concept of “Consent” and ignored the age of consent, which is 18 in the US Virgin Islands. There, Marvin Minsky was accused of sexually assaulting a 17 year old girl. A girl who was apparently provided to him by Epstein.
And Minsky was a scientist working for MIT on artificial intelligence just like Stallman. Shortly after his death, he was accused by one of Epstein’s underage victims but as he was dead, there would not be any case anymore. After all, Minsky can’t defend himself, nor could he be a witness in this case.
So there’s a connection between Stallman and Epstein through MIT and Minsky. And there’s reason to believe that Epstein was part of a huge sex trafficking operation involving minors in the USA and possibly all over the World. An operation that would have to involve a lot of other high-placed people. This is bad when you consider the suspicious way in which Epstein died and the link to some very smart ICT people at MIT, who are working on artificial intelligence. There’s no evidence but there’s ‘smoke’. And smoke tends to mean something is on fire…
Stallman now quit his affiliation with MIT as his single email will damage his reputation and any of his affiliations. To protect MIT, he needed to quit immediately, even though MIT will still be in deep trouble because the rumors will become bigger after this. Because of Epstein and Minsky were related to MIT (Epstein donated a lot of money) there’s a good chance that people will start investigating things that are happening at MIT. After all, this is a place with a lot of young students, many minors, who might be involved in “improper extracurricular activities”. Especially the poorer students might be tempted if they get paid enough. It could be that there are many victims at MIT who don’t want to talk about it because they now have families and well-paying jobs. This will mostly be rumors and it’s not likely that we’ll discover i these rumors are true or not. But Stallman had to go to avoid any future rumors.
Stallman also quit as President of the FSF. And for the same reasons. The FSF will get hurt once Stallman’s reputation gets dragged through the dirt. And with the FSF, the GNU project and the GPL will also become damaged goods. This is because in the near future there will be a lot of attention to Stallman and questions if he harassed or even sexually abused any women. So he needs to distance himself from the FSF to protect it.
Stallman made one single mistake by writing that email. It has ended up in this Vice article, which is basically very damaging already. Reporters are trying to find out more about the connection between Epstein, Minsky, MIT and now Stallman. And maybe even the FSF. A post on Medium makes it even worse.
So, Stallman is falling after one huge mistake. One simple email that draws a shitstorm all over him now. And it is bad! And people will wonder about it. Many will continue to defend Stallman, as they should. He just posted his opinion, even though it’s a very bad opinion. He should not have said it, but he did. And now he pays the price and will need to stay quiet and out of the public eye for a while. As he’s 66 years old now, I would suggest that he’d just retire and will just have public speeches once in a while once the worst part of this all is over.
As for MIT, they will continue to have problems but not because of Stallman. Minsky, Epstein and a few other suspects have already caused enough damage. But as Minsky and Epstein are both dead, it’s very likely that they can get out of these problems as long as no new names pop up. Well, Stallman just popped up, but he’s clean, right? Right? Well, let’s hope so. Innocent until proven otherwise.
And the FSF will need to get a new President. And this president will likely have a different opinion on open source. It will change the FSF and their future. But it’s impossible to tell how they will change.
Still, there’s one more thing Stallman said in the past that will be used against him. On his website, he says something about Dutch paedophiles who created their own political party that would legalize sex with minors, under specific conditions. He said: I am skeptical of the claim that voluntarily pedophilia harms children. The arguments that it causes harm seem to be based on cases which aren't voluntary, which are then stretched by parents who are horrified by the idea that their little baby is maturing.
That won’t make him very popular and will make people more sceptical about his motives. His argument is basically that voluntary sex should be just fine. But no one questions that, hopefully. But people will question if minors can actually volunteer to have sex, assss in most cases they are pressured and forced into having sex. Sometimes by peer pressure, or by adults bringing presents and money. Because it’s so hard to tell if someone really volunteered, we will have to assume the worst when children have sexual relations as their safety comes first.
So, the Epstein affair now caught Stallman and there will be a lot of conspiracy theories in the future. Some will be complete crazy stories and it’s very likely that Stallman isn’t involved in aaaaanaughty business. It’s very likely that he just said something stupid and now regrets it. But he’s falling now and people who try to stop his fall might end up falling with him…
Which is sad, as Stallman was a positive force in the computer world. This whole thing will only create more victims and won’t resolve anything.
Vandaag is het zondag. Zoals gewoonlijk ben ik met mijn hondjes op bezoek gegaan bij mijn moeder. Mijn hondje Lasja was lekker actief maar mijn hondje Cees had het niet makkelijk en was kortademig. Een slecht voorteken maar verder liet hij niets merken. Hij at nog lekker, hij dronk nog wat en het werd gezellig bij mijn moeder.
Nog even de hondjes uitgelaten in de wijk bij mijn moeder, waar Cees nog even ging poepen en snuffelen en hij had er nog duidelijk zin in. Maar we moesten naar huis.
Thuis aangekomen bleek hij het al moeilijk te hebben en was hij kortademig. Maar daarvoor heb ik een hondenkar dus Cees de kar in en naar huis. Maar hij was duidelijk niet goed eraan toe.
Thuis aangekomen had hij geen trek en trok hij zich terug. Ik hield hem in de gaten maar moest ook eten en tijdens het eten merkte ik een zwaar gehijg. Cees zat op bed in de lucht te staren en te en had duidelijk luchtproblemen. Dus direct 144 gebeld voor de dierenambulance en aangegeven dat ze moesten langskomen. Ook via de dierenambulance een nummer gekregen van een spoedarts voor dieren om alvast contact te leggen.
De dierenambulance kwam snel en het was duidelijk dat we direct naar de dierenarts moesten voor een zuurstoftent. Ik had mij al voorbereid en mijn jas al aan en of ik Cees wilde optillen naar de ambulance. Dat was prima.
Met Cees in mijn armen naar de ambulance gegaan, Lasja alleen thuis achterlatend. Op weg naar het Medisch Centrum voor Dieren. Ik stap in, ga zitten en doe een gordel om terwijl ik Cees met mijn arm vast hou. Maar in mijn armen verslapt hij al en op het moment dat de ambulance weg rijdt neemt de ambulancebroeder Cees van mij over en geeft hartmassage. Maar het mocht niet baten.
Het is 21:00 en Cees is vreedzaam in mijn armen gestorven…
I noticed a very interesting post today on LinkedIn and I seriously have to rant about how dumb it really is. But look for yourself first and see if you’re good enough as a developer to see the flaws in it.
This is a preview image for a free course on C++ programming. Now, I’m no expert at C++ as I prefer C# and Delphi but I can see several flaws in this little preview. Yes, even though it’s a very tiny piece of code, I see things that trouble me…
And the reason for ranting is not because the code won’t work. But because the code is badly written. And a course is useless when it encourages writing code badly… So, here it is:
But keep in mind that code can be bad but if it works just fine then that’s good enough. Good developers will go for great products, not great code. It’s just that some bad code makes software development a bit harder… In general, coding practices include the use of proper design patterns and to make sure code is reusable.
So, not counting the lines with just curly brackets, I see five lines of code and two serious problems. And that’s bad. But the flaws are related because the person who wrote this C++ code seems to ignore the fact that C++ supports objects and classes. But it probably works so these aren’t really errors. They’re flaws in the design…
So, the first flaw should be obvious. I see various variable names that all start with a single letter and an underscore. The “m+” seems to suggest that these variables are all related. That means, they should be part of an object instead of just some random variables. The “m_ probably stands for “man” or whatever so you would need a class called “Man” and it has properties like ‘IsJumping’, ‘IsFalling’, ‘TimeThisJump’ and ‘JustJumped’. It suggests that Man is in a specific state like falling or jumping. And as it is a state, you would expect a second class for the “Jump” state. And probably others for “Falling”, “Walking” and other states.
The action triggered is a jump so the Man needs to be in a state that supports a jump. Jumping and Falling would not support this state so if man is in one of those states, he can’t jump. Otherwise, his state is changed to Jumping and that would start the timer. And if the timer is zero then ‘JustJumped’ would be true, right? So, no need to keep that property around.
So, all this code should have been classes and objects instead. One object for the thing that is doing something and various “State” classes that indicates what’s he doing at that moment. The fact that the author did not use classes and objects for this example shows a lack of OO knowledge. Yet C++ requires a lot of OO experience to use it properly and allow code reuse. After all, other items might jump and fall also, so they would use the same states.
The next flaw is less obvious but relates to “Keyboard::IsPressed”. This is an event that gets triggered when the user presses a key. It’s incomplete and there’s a parenthesis in front of it so I don’t see the complete context. But we have an event that is actually changing data inside itself, rather than calling some method from some class and let that method alter any data. That’s bad as it makes code reuse more difficult.
One thing to avoid when writing code is doing copy and paste of code from somewhere else. If a piece of code is needed in two or more places then it should be encapsulated in a single method that can be called from multiple locations. So this event should call a method “DoJump”, for example, so you can also have other calls to this method from other locations. For example, if you also want to support jumping on a mouse click.
Too many developers write events and fill these events with dozens of lines of code. Which is okay if this code is only called at one moment. But it’s better to keep in mind that these event actions might also get triggered by other events so you need to move them into a separate method which you can then call.
That would allow you to reuse the same code over and over again without the need for copy and paste programming.
So, in conclusion, I see a preview for a C++ course that looks totally flawed to me. No errors, just flawed. This is not the proper way to write maintainable code!
For many years I’ve been comfortable knowing that programming is build on just four pillars. These are all you need to develop anything you want and these would be:
Statements, or basically all the actions that need to perform.
Conditions, which determines in which direction the code will flow.
Loops for situations where actions need to be repeated.
Structures to organize both code and data into logical units like records and classes, databases with indices and even protocols so two applications can communicate with one another.
But as I’m developing more and more asynchronous code where you just trigger an action and later wait for the response, I start wondering if there should be a fifth one. So, should there be a fifth one?
Parallel tasks, where two or more flows run concurrently.
It’s a tricky one and if you learned to use flow charts and Nassi–Shneiderman diagrams to design applications then you’ll discover that these diagrams don’t have any popular option to represent parallel tasks in any way. Well, except in the way I just said, by triggering an external event and ignore the result until you need it.
Well, Nassi-Shneiderman does have this type for concurrent execution:
Image by Homer Landskirty, CC-BY-SA 4.0 International.
And flowcharts also have a fork-join model to represent concurrent execution. So these diagrams do provide some way to indicate parallel execution. But the representation is one that suggests several different tasks are executed at the same time. But what if you have an array of records and need to execute the same task on every record in a parallel way instead?
Parallel execution is quite old yet I never found a satisfying way to display concurrency in these kinds of diagrams. Which makes sense as they are meant to define a single flow while parallel execution results in multiple, simultaneous flows. And parallel execution can make things quite complex as you might just want to cancel all these flows if one of them results in an error.
But it is possible to represent them in diagrams for a long time already even though their usage was rare in the past. But in modern times where computers have numerous cores and multithreading has become a mainstream development technique, it has become clear that parallel or concurrent execution is becoming an important standard in programming.
So it’s time to recognize that there’s a fifth pillar to programming now. But mainly because it has become extremely common nowadays to split the flow of execution only to join things at a later moment.
But this will bring many challenges. Especially because forking can result in similar tasks being executed while they don’t have to join all at once either. It basically adds a complete new dimension to programming and while it’s an old technique, it isn’t until recently that mainstream developers have started using it. The diagrams are still limited in how it can be executed while developers can be extremely creative.
Of course, there’s also a thing like thread pools as computers still have limits to how many threads can be executed simultaneously. You might trigger 50 threads at once yet add limitations so only 20 will run at the same time while the rest will wait for one of those threads to finish.
It becomes even more complex when two or more threats start sending signals to one another while they continue running. This is basically a start for event-driven programming, which doesn’t really fit inside the old diagram styles. You could use UML for various of these scenarios but it won’t fit in a single diagram anymore. A sequence diagram could be used to display parallel execution with interprocess communications but this focuses only on communication between processes. Not the flow of a single process. Then again, UML doesn’t even have those kinds of flow diagrams.
So, while programming might have a fifth pillar, it also seems it breaks the whole system due to the added complexity. It also makes programming extremely different, especially for beginners. When you start to learn programming then the four pillars should teach you what you need to know. But once you start on the fifth pillar, everything will turn upside down again…
So maybe I should even forget about my four pillars theory? Or add the fifth one and ignore the added complexity?
It is interesting to see how many people want to start programming as they’ve played with a computer and now want to start making their own games, their own apps and their own websites. So they read about the more interesting programming languages and think they should learn PHP for web development, Java for Android or Swift for IOS. Or some other languages like Python, Go, Rust, C# or any of the other programming languages mentioned in the Tiobe Index. Why? Because these languages are very popular. But most won’t really notice that the Standard C language is also extremely popular yet everyone seems to skip it? The reason is often because the language is considered complex and difficult, it has no object-oriented paradigms, no overloading and no cool graphical libraries or even standard database functionality. Even worse, the book The C Programming Language has less than 300 pages explaining everything you need to know yet whole operating systems are written in it so it must be complex. Yet not, as it fits within 300 pages…
But if you want to learn programming, you should start with standard C simply because it teaches you the basics of programming. Sure, objects and classes are fun, but that’s not code! That’s structure! Code is organised in classes and objects to add more structure to the code you can do more with less code. But to use those structures properly, you must first know what code is.
Remember this line, which I will refer to as Label 1.
And code is simple. You have statements and statements are simple actions. You add two numbers, you show something on the screen or you’ll wait for input. Those are simple actions. They’re tasks and they could be very simple or very complex. But from the code perspective, they’re all tasks.
Next, you will have conditions. Conditions will determine if certain statements (tasks) will be performed or not. If the user pressed a key, close the window. If a file is not found, show an error. And even in real life we see lots of conditions because if the cookie jar is empty, we will have to fill it with cookies again.
And last, you have loops. Basically, the repetition of code. You have done an action but you need to do it again. And again. And again. And rather than repeating the same statement over and over again, you just put it in a loop which will basically run forever. Unless you add a condition to the loop allowing the control flow to just out of the loop.
Like filling the empty cookie jar with cookies. It is empty so you add a cookie. It’s still not full so you add another cookie. And another one. And more. All the way until it is full as you can stop when it’s full.
So basically programming is all about statements, conditions and loops and how control of the actions flows through all of it. And if this is too difficult to understand then read this part again by scrolling up to the line that I refer to as Label 1… If you understand this principle, continue to read.
So, you’ve just learned about statements, conditions and loops so now you know programming! The rest has nothing to do with programming but is all about the structure of code. And that part are the functions and procedures, data structures, objects, classes, interfaces and whatever more. And as you should start practicing, the best thing to start with is a simple programming language that focuses mostly on the programming part and less on structure. And that language is C.
In C the only structural parts you’ll deal with are functions and data structures. And while C is perfect for making operating systems it is also ideal to learn the basics. You can use it to make simple console applications to maintain an address book, shopping list or even a calendar. But the lack of a GUI, database support and classes actually make C harder to learn for people who are already used to those! And it’s time to forget about those things and return to the basics.
One thing to keep in mind is that standard C has some very good build-in functionality for handling dates and times so that makes it perfect for a simple agenda. But the lack of database support means you’d have to do your own file management if you want to store your data for safekeeping and sharing. But a modern computer will have gigabytes of RAM and even a busy calendar is unlikely to have more than a few thousand records of about 100 bytes each. So reading all data in memory should not be a big problem. But file input and output will be required to load and save your data to be sure it’s all safe.
So, how to start? Start by determining what kind of data you’ll be handling. Do this with pen and paper, sitting on your couch with some milk and cookies or whatever else helps you think and stay away from your computer! You start by thinking about what you’re going to make so that computer isn’t needed yet! Design first, structure next and then you can code.
So, the agenda… Say, you want an agenda to keep track of the whole family and where they are and what they’re doing. The agenda part suggests dates and times, the family means persons and the locations means addresses. But what they’re doing is undefined so we just keep it as free text. So, that’s the data that matters.
Next, what kind of control would you like? Well, it will be a console applications so the user will have to type in commands. A nice GUI would be nice but the GUI is not part of the C standard. So command line instructions it will be. Statements like “load” and “save” would be the first important thing. Then, because we’re dealing with data, we need statements to manage it so we will have “Add”, “Modify” and “Delete” followed by “Calendar”, “Person” or “Location”. These statements would almost be SQL like! And we need to be able to show data so that would be either “Show” or “Select” or “Print” or whatever you think sounds nice. Again with an indicator for the right table.
But now things become more challenging as you need indicators for the data records. Say, you want to add a new event so your statement would have a syntax like “Add Agenda <date> <time> <duration> <person_id> <location_id> <free text>” and your code would have to parse it, check if it’s all okay and then add it to the list. And by defining this simple statement you will already know more about your data structure as the agenda record will have a date, time, duration, link to a person, link to a location and some additional text while both the person and location records will have unique IDs. But that’s structure and we’re still designing here.
So we continue defining the actions we want to perform on our data. A “Delete agenda <agenda_id>” suggests that agenda needs a unique ID also. Fine! We have at least three tables and four actions per table (Create, Read, Update and Delete or CRUD) so we have at least 12 functions to define. We don’t care how they are called but we know how we will manage the data. And perhaps we have some alternate versions for these functions as a location might not always be required so we would have two “Add” functions”. Or maybe we want to delete all agenda entries for a person or for a specific day. We’re almost making our own SQL syntax here!
But we won’t go full SQL on our data as we only focus on the things we consider important. We’re keeping things simple and don’t want users to work out all kinds of complex queries as this application needs to be simple.
Interesting will be the saving and loading of the data but my advice would be to just write it all to a simple text file so you can edit it afterwards in notepad or another editor, to fix errors. It means parsing text to data and converting data to text, preferably in some easy way. It’s a good exercise to come up with a good file format.
So once we have the actions we want to perform on our data, we will have to consider what data we actually want. We have three simple tables and we already know the “Agenda” table will link to the other two. For persons, we would like to have a first name, last name, their function and maybe a phone number or birth date. For locations we want the name for the location, address and maybe even the phone extension number for the phone in that room. And while it is tempting to add more tables and stuff into this application, we have to focus on making something first and all we have by now are still notes on paper.
So, now we know what we want to make, how we will control it and what the data will look like, we can start working on the actual code. And the code will be simple as it’s a console application waiting for user commands. User types a command, presses ‘Enter’ and the application starts parsing it and tries to execute any valid command while reporting any errors.
This is a simple programming exercise which also offers plenty of distractions as you likely want to make it prettier. Don’t fall for that trap as you need something to show first! Once you have something to show, that would be version 1 and you can start version 2 now, while version 1 is save in your source control system.
You do use source control, don’t you?
Anyways, this is a project to start to learn programming as it mostly focuses on the programming itself, not the structure. When you start expanding the whole project, you can consider rewriting it in Java or C# or whatever language you prefer that supports OOP. Probably something with a nice graphical shell so the user doesn’t need to type commands but can open dialog windows and use drop-down options to select whatever they want. But all of that isn’t really programming. It’s adding structure. Call it structuring for all I care!
When you want to create applications then you should understand both programming and structuring. But keep in mind that the structure depends on the programming, not the other way around. Too many developers get lost in those structures and make things far more difficult than need be. Then again, too many developers start behind the computer, entering code instead of reading documentation, making notes and don’t think ahead. Or they did think but are trying to do way too much all at once.
Every web developer should know about the Secure Sockets Layer and it’s successor, the Transport Layer Security. (SSL and TLS.) These techniques are nowadays a requirement to keep the Internet secure and to keep private matters private. But while this technique is great, the implementation of it has some flaws.
Flaws that aren’t easy to resolve, though. But to understand, you will need to understand how this technique works when you use it to protect the communication between a visitor and a website.
This is a very long post as it is a complex topic and I just don’t want to split it in multiple posts. So I add several headers to separate parts…
What is SSL?
When you communicate with a website, you’re basically have a line with two endpoints. You on one side and the web server on the other side. But this isn’t a direct line but goes from your computer to your router/modem, to your provider, over some other nodes on the Internet, to the provider of the host, the router of the host to the computer where the host is running the website on. And this is actually a very simplified explanation!
But it shows a problem. The communication between the two endpoints goes over various nodes and at every node, someone might be monitoring the communication, listening for sensitive information like usernames, passwords, social security numbers, credit card numbers and whole lot more. And to make it even more harder, you don’t know if your information will travel over nodes that you can trust! So, you need to make sure that the information you send over between both endpoints is secure. And that’s where SSL is used.
SSL is an encryption technique with asynchronous keys. That means that the host has a private key and a public key. It keeps the private key hidden while giving everyone the public key. You can generally use one key to encrypt a message but you would need the other key to decrypt it again. And that’s basically how security works! You have the public key and you encrypt your data with it before sending it to me. No one on those nodes have the private key, except me, so I’m the only one who can decrypt it. I can then encrypt a response with the private key and send that back to you, as you can decrypt it again with the public key.
Unfortunately, everyone on those nodes can too, as they would all know this public key as I had just sent it to you. So things need to be a little more secure here. Which fortunately is the case. But in general, you should never encrypt sensitive data with a private key as anyone with the public key would be able to read it!
Session keys…
But the Internet uses a better trick. Once you receive the public key from the web server, your browser will generate a session key, which is a synchronous encryption key. This session key can be used by anyone who knows it and right now, you would be the only one. But as you have my public key, you would use my public key to encrypt the session key and send it to me. Now I know it too and we can have a communication session using this session key for security. And once the session is done, the session key can be discarded as you would make a new one for every session.
Most people think the encryption is done using the SSL certificates but that’s not the case! SSL is only used to send a session key to the server so both can communicate safely. That is, as long as no one else knows that session key. Fortunately, session keys are short-lived so there isn’t much time for them to fall in the wrong hands…
The main weakness…
So, this seems pretty secure, right? My site sends you a public key, you create a session key and then we communicate using this session key and no one who is listening in on us can know what we are talking about! And for me it would be real easy to make the SSL certificate that would be used as most web servers can do this without any costs, and generally within just a few minutes. So, what can go wrong?
Well, the problem is called the “Man in the Middle” attack and this means that one of the nodes on the line will listen in on the communication and will intercept the request for secure communications! It will notice that you ask for a public key so it will give its own public key to you instead that of the host. It also asks for the public key of the host so it can relay all communications. You would then basically set up a secure line with the node and the node does the same with the host and will be able to listen in to anything that moves between you, as it has to decrypt and then encrypt each and every message. So, it can listen to sensitive data without you realizing that this is happening!
Authorities…
So the problem is that you need to know that the public key I gave you is my public key, and not the key of this node. How do you know for sure that this is my key? Well, this is where the Certificate Authorities (CA) have a role.
The CA has a simple role of validating the certificates that I use for my website. I want to secure my host so I make a certificate. I then ask the CA to sign this certificate for me. The CA then checks if I really am the owner of the domain at that specific moment or have at least some control over the domain. And when they believe that I’m the owner, they will sign my certificate.
Then, when you receive my public key then you can check the credentials of this certificate. It should tell you if it is for the specific domain that you’re visiting and it should be signed by the CA who issued the certificate. If it is signed correctly then the CA will have confirmed that this certificate is linked to my host and not that of some node between you and me.
Trust…
But the problem is that when your connection isn’t secure because some node is trying to listen than checking if my certificate is properly signed by the CA won’t work, as you would be requesting the CA to validate it over the same unsafe connection. The node will just claim it is so that option won’t work. No, you already need to know the public key of the CA on your system so you can decrypt my signature. And you need to have received the Ca’s certificate from some secure location. Otherwise, you can’t trust if my public key is the real thing.
So most web browsers have a list of public keys as part of their setup. When they install themselves, they will also include several trustworthy public keys from the more popular CA’s. Basically, the CA’s they deem reliable. So your browser will validate any public key from my site with the public keys it knows and trusts and if everything is okay, you will be notified that the connection is secure and the session key can be generated for further secure communications.
Otherwise, your browser will give you a warning telling you what’s wrong with the certificate. For example, it might be outdated or not meant for the specific domain. In general, you should not continue as the connection with the host has security problems!
Distrust!…
But here’s the thing… The list of trusted CA’s in your browser can be modified and to be honest, it sometimes gets modified for various reasons. Some are legitimate, others are not.
For example, this list is modified when a specific CA is deemed unreliable. This happens regularly with smaller CA’s but once in a while, some major scandal happens. For example, in 2011 it was discovered that the company DigiNotar had a security breach which had resulted in several certificates being falsified. Most likely, the Iranian Government was behind this in an attempt to check all emails that their citizens were sending through GMail. The fake certificates allowed them to listen in on all emails using the man in the middle technique. DigiNotar went bankrupt shortly afterwards, as all the certificates they had issued had become worthless.
Similar problems occurred at StartCom, a CA that actually gave away free certificates. The Israeli company was purchased by a Chinese company and some suspicious behavior happened soon afterwards. The fear was that this Chinese company (and perhaps even the Chinese government) would use this trust that StartCom had to make fake certificates to listen in on all communications in China. Both Mozilla and Google started to raise questions about this and didn’t get satisfying answers so they decided to drop the StartCom certificates. This CA had become controversial.
And then there’s Symantec. Symantec is a company that has been making software for decades that all relate to security. It is an American company and has been trustworthy for a long time. And in 2010 Symantec acquired Verisign’s authentication business unit which includes releasing SSL certificates for websites. But in 2015 it was discovered by Google that Symantec had issued several test certificates for impersonating Google and Opera. Further research has led Google to believe that Symantec has been publishing questionable certificates for over 7 years now and thus they announced that they will distrust Symantec SSL certificates in the near future. In April 2018, all Symantec certificates will be useless in Google Chrome and other browsers might follow soon.
Also interesting is that Symantec is selling their SSL business to DigiCert. This could solve the problem as DigiCert is still trusted. Or it makes things worse when browser manufacturers decide to distrust DigiCert from now on also.
But also: Telecom!
But there are more risks! Many people nowadays have mobile devices like tablets and phones. These devices are often included with a subscription to services of some mobile phone company. (T-Mobile and Vodafone, for example.) These companies also sell mobile devices to their customers and have even provided “free phones” to new subscriptions.
However, these companies will either provide you with a phone that has some of their software pre-installed on your new device or will encourage you to install their software to make better use of their services. The manufacturers of these mobile devices will generally do similar things if given a chance. And part of these additions they make to your Android or IOS device is to include their own root certificates with the others. This means that they are considered trustworthy by the browser on your device.
Is that bad? Actually, it is as it allows these companies to also do a man in the Middle attack on you. Your telecom provider and the manufacturer of your phone would be able to listen to all your data that you’re sending and receiving! This is worse, as local government might require these companies to listen in on your connection. It is basically a backdoor to your device and you should wonder why you would need to trust your provider directly. After all, your provider is just another node in your connection to the host.
Did you check the certificate?
So the problem with SSL is that it’s as reliable as the Certificate Authorities who made those certificates. It’s even worse if your device has been in the hands of someone who wants to listen in on your secure connections as they could install a custom trusted certificate. Then again, even some malware could install extra public keys in your trusted certificates list without you noticing. So while it is difficult to listen to your secure conversations, it is not impossible.
You should make a habit of checking any new SSL certificate that you see pop up in your browser and it would be a good idea if browsers would first ask you to check a certificate whenever they detect that a site has a new one. It would then be up to the user to decide to trust the certificate or not. And those certificates would then be stored so the browser doesn’t need to ask again.
Unfortunately, that would mean that you get this question to trust a certificate very often when you’re browsing various different sites and users will tend to just click ‘Ok’ to get rid of the question. So, that’s not a very good idea. Most users aren’t even able to know if a certificate is trustworthy or not!
For example, while you’re reading this blog entry, you might not have noticed that this page is also a secured page! But did you check the certificate? Did you notice that it is signed by Automattic and not by me? That it’s a certificate issued by “Let’s Encrypt“? Well, if the certificate is showing this then it should be the right one. (But when my host Automattic changes to another CA, this statement becomes invalid.)
ACME protocol…
And here things become interesting again. “Let’s Encrypt” gives away free certificates but they are only valid for a short time. This makes sense as domains can be transferred to other owners and you want to invalidate the old owner’s certificates as soon as possible. It uses a protocol called ACME which stands for “Automatic Certificate Management Environment. It’s basically a toolkit that will automate the generation of certificates for domains so even though the certificates are only valid for a short moment, they will be replaced regularly. This is a pretty secure setup, although you’d still have to trust this CA.
Problem is that “Let’s Encrypt” seems to prefer Linux over Windows as there is almost no good information available on how to use ACME on Windows in IIS. But another problem is that this protocol is still under development and thus still has some possible vulnerabilities. Besides, it is very complex, making it useless for less technical developers. The whole usage of certificates is already complex and ACME doesn’t make things easier to understand.
Also troublesome is that I tried to download the ACME client “Certify the Web” for Windows but my virus scanner blocked the download. So, now I have to ask myself if I still trust this download. I decided that it was better not to trust them, especially as I am trying to be secure. Too bad as it seemed to have a complete GUI which would have made things quite easy.
Don’t ignore security warnings! Not even when a site tells you to ignore them…
Additional problems?
Another problem with SSL is that it is an expensive solution so it is disliked by many companies who are hosting websites. It’s not the cost for the certificates, though. It’s the costs for hiring an expert on this matter and making sure they stay with the company! A minor issue is that these security specialists do have access to very sensitive material for companies so you need to be sure you can trust the employee.
Of course, for very small companies and developers who also host websites as a hobby, using SSL makes things a bit more expensive as the costs are generally per domain or sub domain. So if you have three domains and 5 subdomains then you need to purchase 8 certificates! That’s going to easily cost hundreds of euros per year. (You could use a Multi-Domain (SAN) Certificate but that will cost about €200 or more per year.)
Plus, there’s the risk that your CA does something stupid and becomes distrusted. That generally means they will have to leave the business and that the certificates you own are now worthless. Good luck trying to get a refund…
But another problem is that the whole Internet is slowly moving away from insecure connections (HTTP) to secure (HTTPS) connections, forcing everyone to start using SSL. Which is a problem as it starts to become a very profitable business and more and more malicious people are trying to fool people into buying fake or useless certificates or keep copies of the private key so they can keep listening to any communications done with their keys. This security business has become highly profitable!
So, alternatives?
I don’t know if there are better solutions. The problem is very simple: Man in the Middle. And the biggest problem with MITM is that he can intercept all communications so you need something on your local system that you already can trust. Several CA’s have already been proven untrustworthy so who do you trust? How do you make sure that you can communicate with my server without any problems?
There is the Domain Name Service but again, as the MITM is intercepting all your transactions, they can also listen in on DNS requests and provide false information. So if a public key would be stored within the DNS system, a node can just fake this when you request for it. The MITM would again succeed as you would not be able to detect the difference.
Blockchain?
So maybe some kind of blockchain technology? Blockchains have proven reliable with the Bitcoin technology as the only reason why people have lost bitcoins is because they were careless with the storage of their coins. Not because the technique itself was hacked. And as a peer-to-peer system you would not need a central authority. You just need to keep the blocks on your system updated at all times.
As we want the Internet to be decentralized, this technology would be the best option to do so. But if we want to move security into blockchains then we might have to move the whole DNS system into a blockchain. This would be interesting as all transactions in blockchains are basically permanent so you don’t have to pay a yearly fee to keep your domain registered.
But this is likely to fail as Bitcoin has also shown. Some people have lost their bitcoins because their disks crashed and they forgot to make a copy of their coins. Also, the file size of the Bitcoin blockchain has grown to 100 GB of data in 2017 which is quite huge. The whole DNS system is much bigger than Bitcoin is so it would quickly have various problems. Your browser would need to synchronize their data with the network which would take longer and longer as the amount of data grows every day.
So, no. That’s not really a good option. Even though a decentralized system sounds good.
Conclusion?
So, SSL has flaws. Then again, every security system will have flaws. The main flaw in SSL is that you need to trust others. And that has already proven to be a problem. You have to be ultra-paranoid to want to avoid all risks and a few people are this paranoid.
Richard Stallman, for example, is a great expert on software yet he doesn’t use a mobile phone and avoids using the Internet directly. Mobile phones are “portable surveillance and tracking devices” so he won’t use them. He also avoids key cards and other items that allow people to track wherever he goes. And he generally doesn’t access the Web directly, as this too would allow people to track what he’s doing. (He does use Tor, though.) And maybe he’s on to something. Maybe we are putting ourselves in danger with all this online stuff and various devices that we have on our wrists, in our pockets and at our homes.
Thing is that there is no alternative for SSL at this moment so being paranoid is useful to protect yourself. Everyone should be aware of the risks they take when they visit the Internet. This also depends on how important or wealthy you are, as poor, boring people are generally not interesting for malicious people. There isn’t much to gain from people with no money.
Still, people are still too careless when they’re online. And SSL isn’t as secure as most people think, as events from the past have already proven…
As many people have already read, Yahoo had a severe data leak in the past which resulted in ALL YAHOO ACCOUNTS being leaked to hackers. The hack includes sensitive personal information and includes an MD5 hash of the password you’ve used with Yahoo. This is a very serious issue as Yahoo has told me today in an email. It says:
UPDATED NOTICE OF DATA BREACH
Dear Yahoo User,
We are writing to update you about a data security issue Yahoo previously announced in December 2016. Yahoo already took certain actions in 2016, described below, to help secure your account in connection with this issue. What Happened?On December 14, 2016, Yahoo announced that, based on its analysis of data files provided by law enforcement, the company believed that an unauthorized party stole data associated with certain user accounts in August 2013. Yahoo notified the users it had identified at that time as potentially affected. We recently obtained additional information and, after analyzing it with the assistance of outside forensic experts, we have determined that your user account information also was likely affected. What Information Was Involved?
The stolen user account information may have included names, email addresses, telephone numbers, dates of birth, hashed passwords (using MD5) and, in some cases, encrypted or unencrypted security questions and answers. Not all of these data elements may have been present for your account. The investigation indicates that the information that was stolen did not include passwords in clear text, payment card data, or bank account information. Payment card data and bank account information are not stored in the system we believe was affected. What We Are Doing
In connection with the December 2016 announcement, Yahoo took action to protect users (including you) beyond those identified at that time as potentially affected. Specifically:
Yahoo required potentially affected users to change their passwords.
Yahoo also required all other users who had not changed their passwords since the time of the theft to do so.
Yahoo invalidated unencrypted security questions and answers so they cannot be used to access an account.
We are closely coordinating with law enforcement on this matter, and continue to enhance our systems that detect and prevent unauthorized access to user accounts.
What You Can Do
While Yahoo already has taken action to help secure your account, we encourage you to consider the following account security recommendations:
Change your passwords and security questions and answers for any other accounts on which you used the same or similar information used for your Yahoo account.
Review your accounts for suspicious activity.
Be cautious of any unsolicited communications that ask for your personal information or refer you to a web page asking for personal information.
Avoid clicking on links or downloading attachments from suspicious emails.
Additionally, please consider using Yahoo Account Key, a simple authentication tool that eliminates the need to use a password on Yahoo altogether. For More Information
For more information about this issue and our security resources, please visit the Yahoo 2013 Account Security Update FAQs page available at https://yahoo.com/security-update.
We value the trust our users place in us, and the security of our users remains a top priority.
Sincerely,
Chris Nims
Chief Information Security Officer
And yes, that’s bad… it’s even worse as the hack occurred in 2013 and it has taken Yahoo 4 years to confess everything about the hack. Well, everything? I’m still not sure if we’ve heard everything about this case. Worse, as Verizon recently took over Yahoo for a large sum of money, it could even have an impact for anyone using the Verizon services.
But there is more as people might not realise that the sites Tumblr and Flickr are also part of the Yahoo sites. We know that Yahoo is hacked but how about those other two sites? As I said, we might still not know everything…
About to drown by failing security.
Well, assume the worst. While we might be arming ourselves properly against any of these kinds of hacks, we also chain ourselves to the security provided by companies like Yahoo. And those security measures might not protect us against everything.
Fact is that Yahoo has become great and is becoming even bigger now they’re part of Verizon. As a result, all those 3 billion accounts are now owned by Verizon and we better hope that Verizon will use better security than Yahoo ever did. If not, anyone who ever used Yahoo, Tumblr, Flickr or Verizon might soon drown in security problems as their accounts have been hacked and they will continue to hack those.
Is there a solution to this problem? That’s a good question as there are many other companies that we rely upon for our security. Twitter, Google and Facebook are a few popular sites that are also popular targets for hackers. However, as long as these large corporations immediately notify all users if there’s a serious data breach and immediately respond by increasing security, the risks should be acceptable. What Yahoo did was wrong as it took 4 years before they finally admitted the truth!
So in my opinion, Yahoo has to disappear. It is unacceptable that any company with such a major role on the Internet regarding security is trying to hide the truth and keep people vulnerable instead of responding immediately. So instead of following Yahoo’s advise and change your password, I suggest everyone just close their Yahoo account. Permanently! You might still keep your Flickr and Tumblr account as those might not be involved in this hack but Yahoo should go.
And let’s hope that someone will improve the security on both Tumblr and Flickr as these services are highly popular all over the World.
I generally stay far away from religion but I do like discussions about religion. And recently, I got involved in a discussion with some fanatic who “knew” he was right and I was wrong, as his Religious counselors have told him so. So I came up with a simple riddle which he could not answer.
It starts with three Holy Men and a large chest. And as I’m talking about religion in general, I make them of three different religions so we have a rabbi, a priest and an imam. But if you talking to a fanatic, make them all Holy Men for his specific religion.
The rabbi starts and opens the chest to look inside. Once he has seen what is inside, he closes the chest and tells you there’s a statue of a golden calf inside, with precious jewels for his eyes. He describes it in details and he sounds very convincing.
Next, the priest opens the chest and looks inside. After he has seen the content he closes it and tells you what is inside. It is a wooden cross with long, silver nails and a golden hammer. And he too describes it in a lot of details and sounds very convincing.
Last, the imam opens the chest and looks inside. He has seen the content and closes the chest and tells you what is inside. It is a marble statue of a horse with a crescent moon next to it made from pure silver. And it is described in details and also sounds very convincing.
Now, who do you believe? How do you know who is telling the truth?
It’s actually a simple riddle. But for some people, it is still too complex. When they’re from a christian background they are more likely to believe the priest. Jewish people would favor the rabbi. And muslims will believe the imam. But all we know is that at least two of these Holy Men are lying. And maybe all three of them are lying.
When you’re not biased by any religion, it becomes more challenging and you would try to find out how reliable these Holy Men are. You talk with them and look at their actions. Have they committed crimes in the past? Have they been caught lying in the past? And what are they describing exactly? And how about their family? Are they from families that have used lies and crimes in the past?
It takes some time to evaluate who is speaking the truth and as all three of them are very convincing you could just decide to believe all three. However, you know that two of them must have been lying, as not all three objects could have been in the chest.
Or could it? Could it be a magical chest which shows the content that the viewer wants to see? If so, all three of them would have spoken the truth but it requires the chest to be very special. And it makes the content of the chest questionable in value, as what worth does an illusion have?
Or you just don’t care about what’s in the chest. That’s actually the easiest solution. However, all three holy Men tell you that you have to believe one of them as your eternal soul would be in danger if you don’t. All three threaten you that you will go to Hell if you don’t believe in him or believe any of the other two. And that makes it even more challenging as you don’t want to spend your eternal life in Hell.
But if you don’t believe in a soul and eternal life then not even that matters. So the holy Men are telling you to believe them or else they will end your life. You have to believe one or choose death. And if you pick one, the other two will want to kill you, but the Holy Man whom you believe will try to protect you. With the threat of violence and danger for your eternal choice, you will be in big problems and will be forced to make a decision.
So, you wouldn’t make a choice on whom you believe, but you choose the one who is most beneficial for you and your family. You have no choice as you need protection and each Holy Man can provide protection. But when you chose one, the other two will become your enemies.
So you have a big dilemma. You are forced to choose one and will have to believe what he said about what’s in the chest. And this is the same problem as you see with religion. You have basically thousands of “holy men” claiming they, and only they, know the Truth and that you have to believe them, or else. And instead of having just two enemies you would end up with potentially thousands of enemies if you chose to believe one of them. They they will also be enemies if you don’t believe any of them. However, when you follow just one then he will likely protect you against the others.
Or not, as many holy men will actually use those who believe in him to convince them that the others are lying and thus deserve to die. They need to die because they don’t believe in what he is claiming. He knows the truth as he has looked into the chest. And you believe him because you think he’s trustworthy. Right?
Generations later, your children will continue to follow the children of this holy Man, as you’ve educated them to believe in what he told so they believe in what you told them. However, the Holy Man now has three children. And each child tells the story about the content of the chest differently again. One repeats what his grandfather has told. The second one adds a collection of gems and golden coins to the content. The third mentions flasks of wine as part of the content in the chest. And your children will have to make the same choice again as what you had to do. They have to solve the Riddle of the Holy Men.
And this explains why we now have so many different forms of religions. Why we have so many different opinions and don’t know what’s in the chest, as we don’t know whom we really can trust. This is a riddle that will repeat itself every generation, as new Holy Men will be born and each of them claim something different in the content of the chest. All these problems simply because we have to chose whom to believe.
Or do we? The solution of the riddle is actually quite simple. You yourself go to the chest and you yourself will open the chest and look inside. Then you will see what is inside. And when you want others to know what is inside, you will invite them to also take a look inside and keep the chest open. That way, every person can learn what is inside the chest without relying on what others claim they saw.
And that’s what’s science is! In science, you don’t present any beliefs but you show everyone the clear facts and allow them to evaluate the reality themselves by telling them what to do to see those facts. And you allow people to think for themselves and determine for themselves what they are seeing. You suggest theories and others might believe those theories or not. If they want, they can make up their own theories and that’s just fine. Everyone can see inside the chest and see the content.
So the answer of finding the truth is simple. You just have to look for yourself!
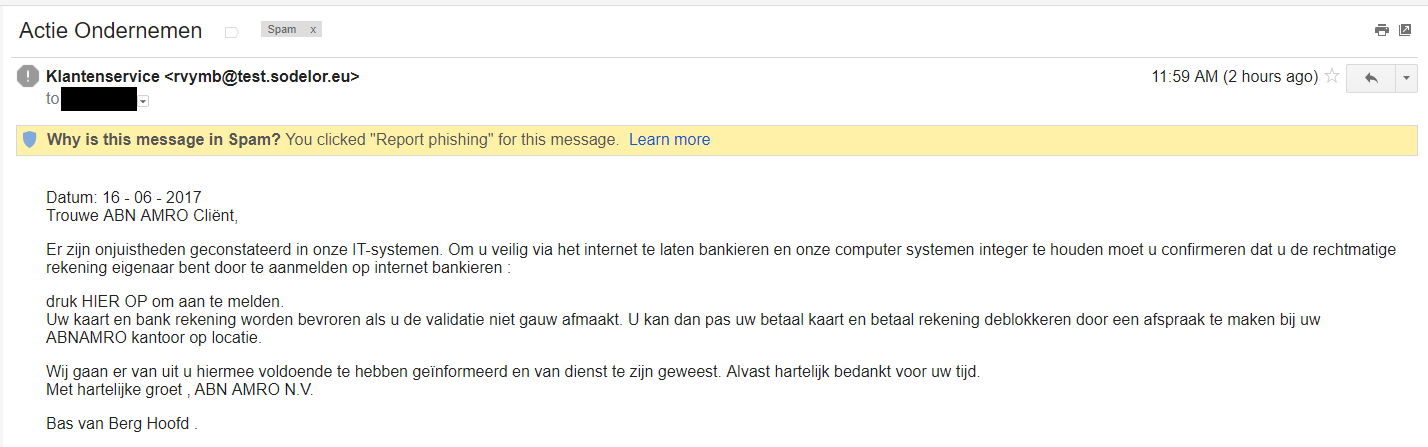
(Dutch warning about a phishing email targeting ABN-AMRO customers. As it targets Dutch people, I write it in Dutch. Sorry…)
Vandaag weer een spam-bericht in mijn spambox ontvangen waarin men weer probeert om mensen op een link te laten klikken. Ik heb het maar meteen als “Phishing” aangemerkt maar het is een beetje onbegrijpelijk dat mensen hier soms toch intrappen want als je goed oplet zie je dat er niets van klopt!
Eerst en vooral komt de email binnen op een account die ik niet gebruik voor deze bank, hoewel ik er wel een account heb. Dit toont maar weer eens aan hoe praktisch het is om je eigen domeinnaam te hebben met een catch-all mailbox zodat je een oneindig aantal email adressen kunt aanmaken.
Andere waarschuwingen zijn de spaties in de datum, de titel “Trouwe Cliënt” en enkele andere taal- en stijlfouten in de tekst. Zo klinkt “betaal kaart” best raar als het om een betaalpas gaat. Duidelijk een gevalletje Google Translate.
Ook het verhaal erachter is vreemd want de bank heeft problemen in hun IT systemen en daardoor moet de klant opeens actie ondernemen? En zolang dat niet gebeurt is de account geblokkeerd?
Interessanter wordt het als je de bron van de email beter gaat controleren. De afzender maakt gebruik van een sub-domein van sodelor.eu en mogelijk is dit gehele domein een phishing-site. In ieder geval heeft het sub-domein een phishing pagina waarin het PayPal nabootst. Sowieso zou je PayPal als afzender verwachten, maar goed. Sommige mensen zijn idioten…
De email bevat ook een URL die verwijst naar een Russische website en dat verbaast mij niets. Russische domeinnamen worden vaak door hackers misbruikt omdat deze vaak eenvoudig te hacken zijn.
Als je verder de bron nakijkt zie je dat deze via de Duitse kundenserver.de worden verstuurd. Dit domein is ondertussen al op diverse blacklists geplaatst wegens de grote hoeveelheid spam die ermee wordt verzonden.
Maar goed, de meest duidelijke detectie dat dit spam is, is omdat het in mijn spam-folder zit.